Selecting storage systems
At the core of your entire solution is the storage layer. Build this correctly and your entire solution will run smoothly, build it incorrectly and it will be extremely difficult to solve and will plague your solution. Leverage GCP native services to ensure a high quality and cost-effective storage solution.
Topics Include:- Analyzing data access patterns
- Choosing managed services (e.g., Bigtable, Cloud Spanner, Cloud SQL, Cloud Storage, Firestore, Memorystore)
- Planning for storage costs and performance
- Lifecycle management of data
GCP Professional Data Engineer Certification Preparation Guide (Nov 2023)
→ Storing the data
→ Selecting storage systems
Topic Contents
Analyzing data access patternsChoosing managed services (e.g., Bigtable, Cloud Spanner, Cloud SQL, Cloud Storage, Firestore, Memorystore)
Planning for storage costs and performance
Lifecycle management of data
Analyzing data access patterns
Data should be readily available, of high quality, secure, and in compliance with privacy and legal regulations. When you're developing your data engineering solution, be sure to understand who is accessing your data and how to ensure high performance of your data product.
Analyzing Data Access Patterns
Data access patterns are how and when users interact with the data stored within your GCP assets, such as GCS. Understanding data access patterns is crucial for determining which storage technology best serves your particular use case or scenario.
For example, if you are running a dynamic and frequently updating website which requires sub-second operations across hundreds of objects, such as a social media site, then using a storage option such as GCS would be insufficient at best. However, if you are performing deep learning upon a billion row dataset using SparkML then GCS would be a perfect back end storage option.
Commonly, data access patterns analyze three key variables:
- How much data is accessed per request.
- What kind of data is accessed, such as Document data or structured tabular data.
- How often the data are accessed.
It is also wise to note who is accessing which data to determine security, encryption, and privacy requirements.
Different data access patterns require different technologies to facilitate them. Essentially, the more you understand your user's requirements, and the more you understand all the core technologies at GCP, the better you will be at developing data engineering solutions.
Choosing managed services (e.g., Bigtable, Cloud Spanner, Cloud SQL, Cloud Storage, Firestore, Memorystore)
GCP hosts a number of core native data technologies which are commonly regarded as best in class among cloud providers. Each service is mature and high-performant. Be sure to understand each service, their trade-offs, and most common use cases.
Google Cloud Platform (GCP) is a capable platform for all cloud data engineering use cases. One of the key requirements of data engineering tasks is effective management of data storage. GCP offers a number of technologies which can be used to satisfy key customer requirements for security, efficacy, efficiency, privacy, availability, and durability.
GCP offers the following storage options:
- Google Cloud Storage (GCS) - This is the primary object storage storage solution for GCP. It is a global system with high availability and durability, and it is used to hold static files such as text files, images, or video. Any static object can be stored within GCS and be read by any processor within Google Cloud. It can also be accessed over the internet via the Cloud Storage JSON API.
- Firestore - Firestore is a NoSql solution for housing dynamic NoSql data. It is designed for massive scalability and dynamic access to frequently read and mutated data. Firestore is mainly used to power websites and mobile applications. Its easy set up and extensive add on library are ideal for developers who want to get a site or app up quickly and don't require a highly customized back end system to house data.
- Datastore - Datastore is the ancestor to Firestore, but it is still available as a selectable option when standing up a firestore back end. However, Google Cloud has noted that Cloud Datastore databases will be automatically upgraded to Firestore databases in the future. It is doubtful that at this point you would see Datastore on the exam, but it is worth noting regardless as the technology could still be utilized.
- Big Query Storage API - Big Query can be used to house structured and semistructured data via their Storage API. The BigQuery Storage API can be utilized instead of, or in addition to, other storage options within GCP. Storage API is most often used to handle streaming data.
- Bigtable - Bigtable is a HBase-compatible NoSQL database which stores data as key-value pairs. It is often used to handle wide and sparse column datasets for use with Dataproc to perform batch based analytics using tools such as Spark or Hadoop.
- Cloud SQL - Cloud SQL is GCP's managed RDBMS server. It is used mostly for transaction data management
- Cloud Spanner - Cloud Spanner is GCP's ACID compliant, globally scalable relational database system. Usually customers move to Cloud Spanner once they outgrow Cloud SQL.
- Compute Engine Storage Options - Compute Engine is GCP's standard VM service. There are several storage options for Compute Engine
- Persistent Disk - High performance and redundant network block storage. This is a fully managed, general purpose storage solution for VMs and is generally good enough for the vast majority of use cases.
- Hyperdisk - Persistent disks with customizable options such as Provisioned IOPS for high throughput workloads.
- Local SSDs - Local SSD's are physical drives attached to the same server as your VM. These are used when persistent disks are not a viable option, such as with specialized security or privacy concerns. These are ephemeral drives and only last the life of the instance.
- Filestore - NFSv3 compliant network file system. This is usually used to provide a convenient interface between Compute Engine and on premises workstations.
Cloud Storage
GCS Introduction
Google Cloud Storage, aka Cloud Storage or GCS, is the standard object storage solution available on the Google Cloud Platform. GCS is a highly available, durable, and globally available object storage solution which can be accessed by any process on the planet quickly and reliably. GCS holds static data such as text files, audio, video, or other objects. It is designed for quickly, durably, and securely storing massive amounts of data while also providing easy and consistent access to that data.
Cloud Storage is a vey effective and general purpose solution for a wide range of data engineering tasks in GCP. It can store any type of object from text files to video files. Its API is very effective at querying, serving, ingesting, and storing data in GCP. Data stored in GCS can be readily served to almost any native process in GCP including data analytics in Dataproc or BigQuery to Vertex AI for machine learning pipelines.
GCS is very low cost and highly efficient storage and it is well suited as a general purpose storage solution. GCS has "11 9's" of durability which means that a loss of data is effectively impossible. GCS is generally more well suited to batch or archival solutions rather than a streaming solutions. GCS provides file versioning which helps prevent accidental deletes or file overwrites. GCS stores data in globally unique buckets which can be replicated and accessed in most places on Earth.
GCS is ubiquitous across nearly all Google Cloud applications and has a wide variety of use cases. Some of the most common ones are for archival storage, housing data which needs to be globally available, as a static website host, or as a highly efficient replacement for HDFS in Cloud DataProc.
GCS Architecture
GCS has a standard architecture which consists of objects contained within a globally available and globally unique container known as a bucket. The objects contained are atomic and immutable which means that the entire object must be acted on by a single request. For example, if you are storing a text file in GCS, you cannot open the file, change a line in the file, and then save the file. You would have to download the whole file, open the file, change the line, and then upload the file back into the bucket, which actually replaces the original copy in GCS.
Buckets and bucket names are globally unique. You cannot have the same bucket name for multiple buckets. It is a good practice to break down hierarchies across URI namespaces rather than across buckets, and store data across atomic scalars demarcated against the prefixes attached to the objects. Although GCS is similar in nature to a file system it is not an NFS system. If you require a filesystem then you should look at Filestore instead.
GCS is highly available and durable object storage. Durability is how likely your object is to not be deleted or lost or become corrupted in some way. GCS has "11 9s" durability of 99.999999999% for all storage classes and object types. Availability is defined as the "readiness" of the data to be retrieved from the bucket. Retrieval speed is how fast the data are retrieved from storage when queried and is typically less than tens of milliseconds to first byte. GCS is unique among cloud providers in that retrieval speed and availability are very similar across storage classes.
GCS buckets are globally unique, but they can be stored in different geographical arrangements. GCS buckets can be stored as multi-region, dual-region, or single-region. There are slight differences in price between these, but the primary concern for most customers are privacy and security. For example, the EU and the US often have differences in data privacy requirements, and customers can choose to not host data in EU servers to avoid regulatory issues. Availability is also greater for multi-region or dual-region vs single region, but availability is never less than 99.0% for all location types and storage classes. For standard class data the typical monthly availability is over 99.99% for all location types.
Firestore
GCP Firestore is a NoSQL document database designed for powering websites and mobile applications. It is scalable to millions of requests per second and effectively captures event data for querying. Data is stored in "documents" which are highly dynamic field representations of mutable data. Firestore data is easily queried via REST API calls using the Google Cloud SDKs. Firestore is the successor to datastore and the recommended database engine when developing new applications.
Although Firestore is ACID compliant on a document-level, it isn't a relational database, and its schema isn't designed to maintain referential integrity and data consistency across documents. It is possible to use transactions in Firebase which will perform atomic operations on a set of documents, but this is not the same as a primary key and foreign key relationship often found in RDBMS databases. Firestore does not contain processors to determine dependencies for analyses, does not lock tables or rows for transactions, and doesn't work to maintain database consistency.
It is possible to capture the events that result from updates to firestore documents. CRUD operations trigger events which can be captured by cloud functions and then streamed directly into Big Query, PubSub, or instantiated into GCS. This method of event streaming is fairly common and it is worth noting here. An example would be a customer placing an order on your website. The order creates a firestore document which then triggers an event. This event data is sent to Cloud Functions which then pushes that data into Big Query. The analytical event data can then be queried with Standard SQL.
Firestore is a NoSQL document database and is the successor to Datastore and the "Realtime Database". It is used to house web application data and process ACID transactions for web and mobile applications. Compared to Bigtable it is more focused on providing services for web applications, and especially for mobile websites. As a document database it can support ACID transactions against a document and ensure proper strong-consistency across all receiver nodes.
Firestore integrates well with the overall Firebase suite of application tools. Firestore offers a wide range of extensions which can help facilitate development and can help stream data into an analytical tool, such as BigQuery. Firestore can be configured with advanced security rules which can ensure data integrity and security while in operation.
Memorystore
Cloud Memorystore is a NoSQL in-memory database used as a caching service for Redis and Memcached. It is a high throughput, high reliability, and highly available caching service. Cloud memorystore is used for caching essential data on the edge in order to cut down data retrieval latency and improve data operations for high frequency applications, especially games, high frequency trading applications, and data hungry web applications, such as Youtube. Memorystore is often used to speed up commonly accessed API queries. For example, if you want to return the top 10 streamed artists for the last day as part of a landing page for users then you can use Memorystore to cache this query and return it much more quickly than if you queried it directly from a database or even Bigtable. Memorystore can also be used to take pressure off of transaction databases by caching commonly used queries.
If you use Memorystore for Redis you can take advantage of the Redis RDBMS which can ensure strong consistance and atomic transactions.
Memorystore is used commonly used to house ad hoc data close to the edge when running high-performance applications, such as Massive Multiplayer Online games. It is also used as a low latency cache for streaming data and works well with dataflow.
Memorystore requires a good amount of day to day monitoring to ensure peak performance. Memory fragmentation is a real concern, so you have to monitor the instance to ensure that any fragmentation is remedied quickly or you could hit an out of memory error and the database will become faulty or unresponsive.
Memorystore is easy to set up and get started with. An example pipeline could be to use memorystore to store temporary data when processing application data, such as a user session in an e-commerce site. Then, once the user transaction is complete, such as a purchase being made, the data is persisted in firestore document database or the data is published to a Pub/Sub topic for downstream processing.
There are various tiers for Memorystore in GCP. All include nodes with up to 300 GBs of data allowed and up to 16 Gbps of memory bandwidth.
| Tier | Max Size (GBs) | Memory Bandwidth (Gbps) | High Availability? | Read Replicas? |
|---|---|---|---|---|
| Basic | 300 | 30 | No | No |
| Standard | 300 | 30 | Yes | No |
| Standard With Read Replicas | 300 | 30 | Yes | Yes |
BigQuery Storage API
BigQuery is a serverless and effectively infinitely scalable cloud data warehouse for GCP. One of the components which makes BigQuery so powerful is its storage system which is highly optimized and efficient. But, until recently, data had to be read through another process before entering BigQuery's storage system. The introduction of the BigQuery Storage API has solved this bottleneck by allowing direct and optimized read and write operations to Colossus without having to query BigQuery itself. This has made storage operations easier, faster, more efficient, and cheaper.
BigQuery is GCP's massively scalable and serverless Cloud Data Warehouse. It can handle petabyte scale analytical queries and can read from a wide array of data sources. As a columnar data warehouse BigQuery can host wide tables with thousands of columns while only having to read specific columns during query execution.
BigQuery's Storage API is great for ingesting and exporting data and can be configured as a subscriber to Pub/Sub to facilitate streaming data. BigQuery can read from GCS, Cloud SQL, or Bigtable natively as an external table.
BigQuery Read API
The BigQuery Read API streams data from BigQuery tables to applications requesting data from BigQuery storage. It uses an rpc session based protocol to execute read operations from BigQuery tables. Note that it is only possible to read from actual BigQuery tables. it is not possible to read data from a view or an external table as these are not technically instantiated in Colossus. For these you would have to instantiate the views or external tables directly or use BigLake tables.
BigQuery Write API
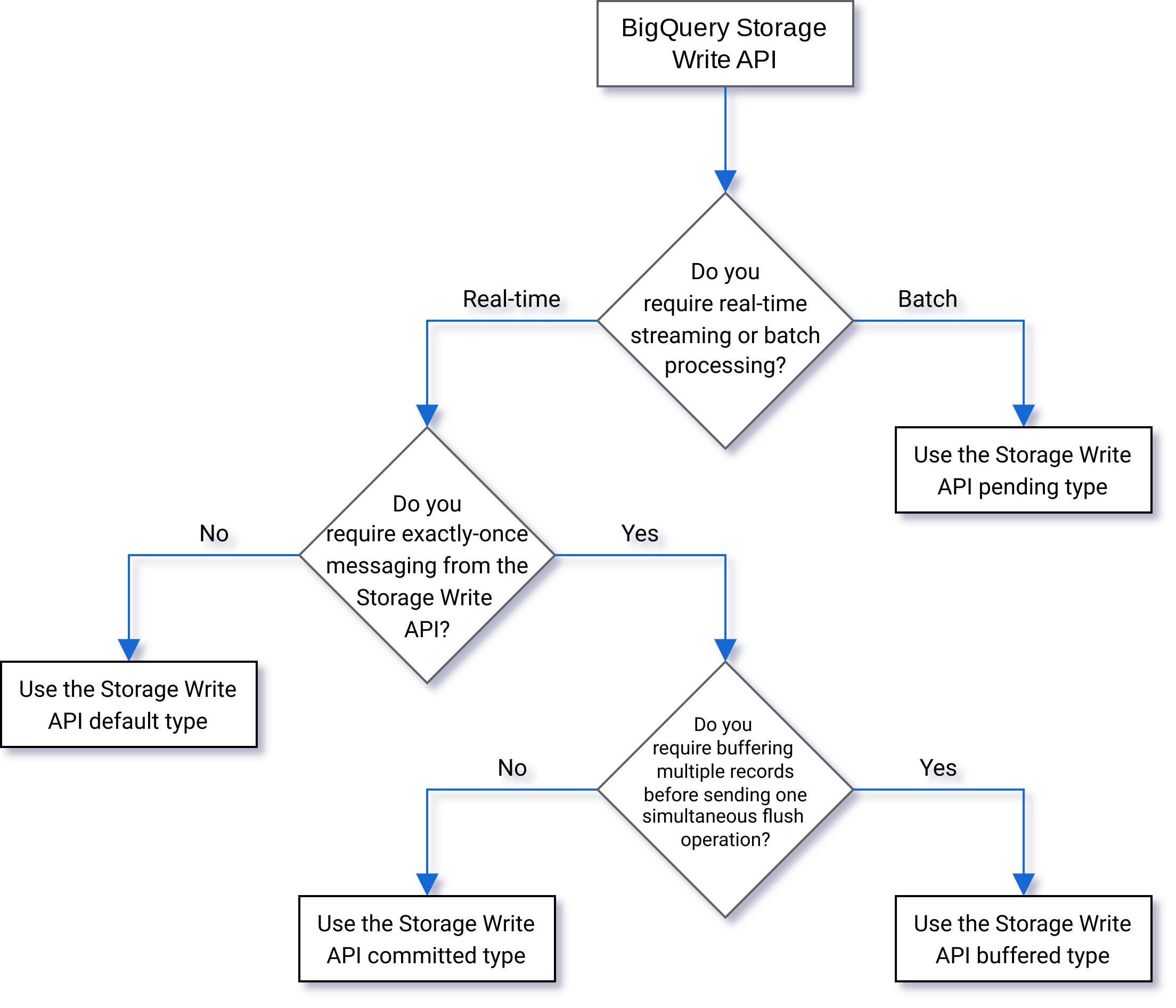
The BigQuery Write API is used to create a unified streaming ingest or batch loading engine for directly streaming data into a BigQuery table. This is a much more efficient operation compared to normal table instantiation processes such as copy into commands.
Data are streamed directly into BigQuery tables. Most use cases can be solved by using a default stream. This stream is an append only, at-least-once method which doesn't check for duplication.
Use Application-created streams to develop fine grained parameterizations for streams. This allows you to batch commit streams, check for exactly-once semantics, or use data buffering.
BigTable
Google BigTable is a NoSql database engine which represents data as key-value pairs. Data in BigTable are stored in a wide column format as sparse data. It is possible to have thousands of columns attached to a single row key, even if 99% of those columns are null values.
BigTable is primarily used to store data for mass scale applications in Google such as Google Maps. In the data engineering space, you may see it as a pathway to migrate HBASE datasets to GCP. BigTable is also used to house IOT data and time series data.
BigTable is a NoSQL solution for housing data which requires single-digit millisecond operations across potentially billions of rows of data. It is used for website indexing, maintaining web application state data, HBASE data, time-series data, or other event data.
As a wide column, sparse dataset, Bigtable is extremely fast at hosting highly mutable NoSQL data. It is used throughout Google with a multitude of applications including Google Analytics, Maps, Gmail, Youtube, and it is also the base technology for Cloud Spanner. On the exam, expect questions to mostly be about Bigtable architecture and operations, such as how to address hot-spotting issues, designing row-key indexes, column family design, or efficient use of nodes.
Bigtable is often used to perform analyses of time-series data using tools like Grafana.

Schema Design
BigTable row-indexes are unique row identifiers which BigTable uses to look up the data it needs. Row-keys should be created to suit the queries you expect to be run against the data. Row-keys and can be made composite by inserting a logical delimiter, such as a #. An example is looking up geographic data by city. When you're looking at a city name, such as Paris, you want to first pull all rows for the city Paris. However, there is more than one Paris in the world. Therefore you should add a delimiter to allow BigTable to easily identify which Paris you're asking about.
An example row key would look like this:
- Paris#Texas
- Paris#France
Row-Key Design
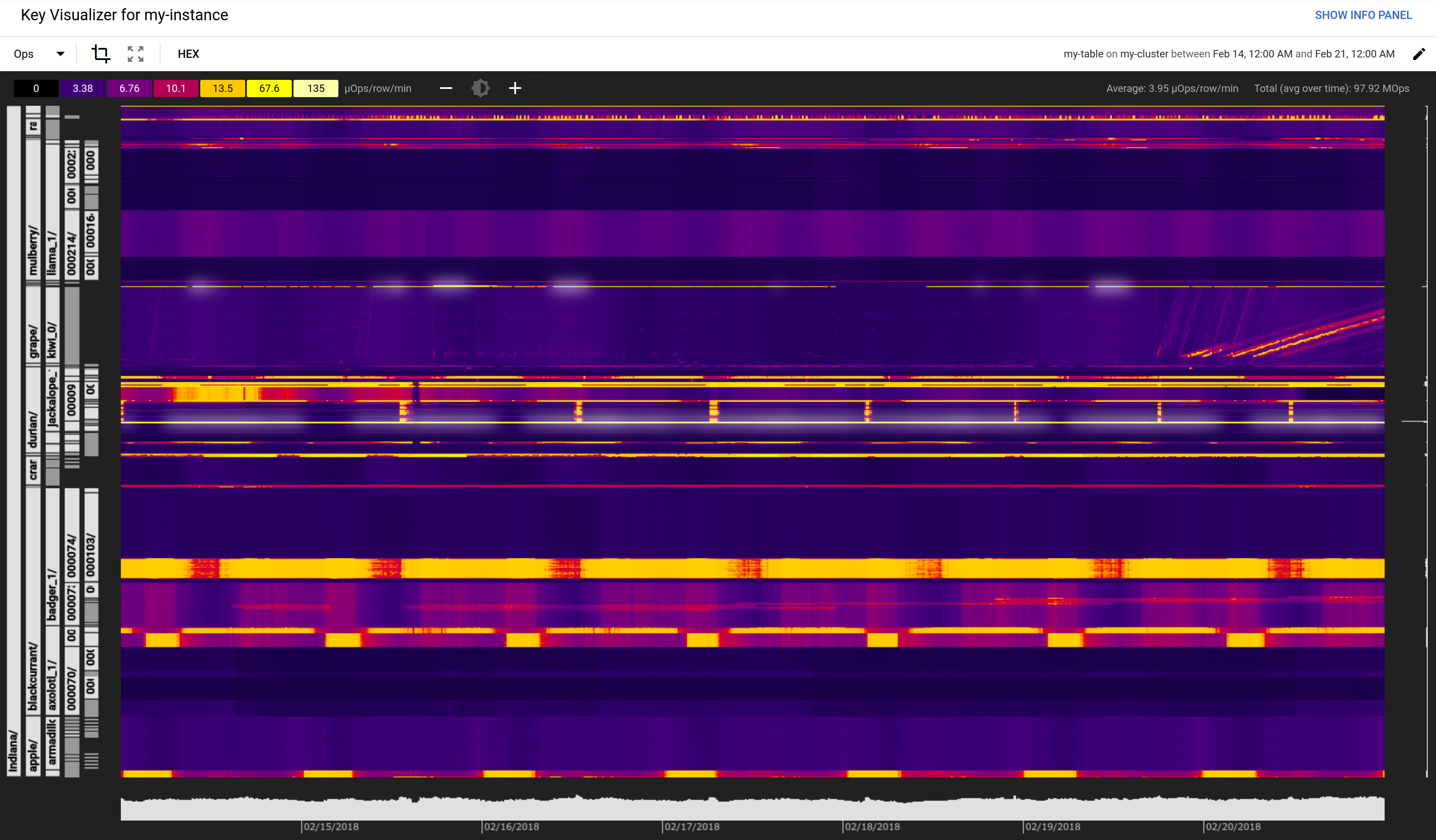
Hot-spotting is an anti-pattern in BigTable where improper row-key design leads to node reads and writes becoming imbalanced. This is often due to sequential row-keys being used, such as an integer sequence or timestamp. When building a row-key index for BigTable you should work to avoid hot-spotting to achieve the full benefits of scalability. Google Cloud Platform offers a number of tools to detect and relieve hot-spotting issues in BigTable, but by following the rules in row key design philosophy you can avoid the vast majority of hot-spotting issues. You should create row keys grouped by the dimensions you expect to be frequently needed by the application, but with a thought between balance in cardinality and clustering by dimension, rather than by time.
Avoid the following anti-patterns:
- Row keys that start with a timestamp
- Row keys that cause related data to not be grouped
- Sequential numeric IDs
- Frequently updated identifiers
- Hashed values
- Values expressed as raw bytes
Use the BigTable Key Visualizer to detect hot-spotting issues.
BigTable architecture
BigTable consists of Instances, Nodes, and Clusters. A Bigtable instance is a project level global resource manager which maintains and manages all of your BigTable clusters and tables.
A BigTable Cluster is a compute cluster contained within a zone. Typically, in a high-availability set up, you would have at least two clusters deployed to two separate zones. You could also choose to deploy a cluster in as many as 8 regions. Each table is associated with each cluster in your instance. All tables are assets belonging to the instance, not the cluster.
BigTable nodes are the actual compute hardware which processes requests against BigTable. If performance starts degrading, you could Datastream. This gives the security of transaction handling using Cloud SQL's relational schema while ensuring scalable and fast analytics using Big Query's columnar schema.

Cloud SQL is an RDBMS which operates on a single machine and a single hard disk. Cloud SQL will automatically scale up your storage up to 64 TB as required so you don't need to worry about right sizing storage before launching Cloud SQL. As your data grows it might become necessary to upgrade the instance itself, but this is also a very easy process.
Cloud SQL can be set up with an HDD or SDD. Use HDD if you need a low cost option which doesn't require high performance row reads. A good use case is analytical processing which processes a lot of sequential rows of data. This will lower the need for the disk seek head to jump between address spaces. Use SDD for relatively cheap and effective storage suitable most general use cases.
A common architecture in the cloud is to use Read Replicas to lighten the load on your main writer instance and provide high availability to handle fail over scenarios. Replication can also be cross-regional which will give low latency reads and high-availability across regions.
Use Cloud SQL Auth Proxy to provide a secure connection to Cloud SQL without having to set up authorized networks or configure SSL. This is somewhat akin to operating a direct VPN connection to Cloud SQL. You can use IAM to authenticate with Cloud Auth by giving the proper role.
Cloud Spanner
Cloud Spanner is a fully managed and globally scalable relational database system. Cloud Spanner is unique in that it can handle transactions from anywhere in the world and provide near instantaneous ACID-compliant transactions without having to traverse the internet to access a Cloud SQL instance. Cloud Spanner offers 99.999% availability and strong transactional consistency. Most Customers move from Cloud SQL to Cloud Spanner once they have outgrown their Cloud SQL instance or require global accessibility.
Although an intricate understanding of Spanner architecture and operations are not required for the exam it is still worth reading.
Schema Design
Cloud Spanner is essentially a relational database system capable of ACID-compliant transactions on a global scale. Therefore, schema design is very similar to what you would see in a standard RDBMS such as SQL Server or Oracle.
Some specific schema considerations for Spanner are table interleaving and the concept of foreign keys. Table interleaving is an important consideration for Cloud Spanner which can make your transactions much more efficient. Table interleaving is a design where parent and child rows are physically colocated in storage making for much faster transactions. Foreign keys are a familiar concept to RDBMS engineers and behave the same way. Google recommends choosing either foreign keys or interleaving, but not both.
One important difference between Spanner and standard RDBMS is the selection of primary key candidates. Cloud Spanner is subject to hot-spotting when interacting with frequently accessed data. For example, many database schema designs have a sequential number as a primary key. This is actually not ideal for spanner as it will funnel insert transactions into a single node. Instead you should consider hashing the primary key, using a UUID, or reversing the column order of composite primary keys.
Cloud Spanner is a globally available and highly scalable RDBMS. It is built on top of Bigtable which is inherently a NoSQL solution, but the Spanner software is engineered in a very clever way to give a transactional and ACID-compliant architecture to the database. When compared to a "true" RDBMS, such as Cloud SQL, Cloud Spanner lacks the true locking mechanisms and guarantees provided by a RDBMS database. Instead it relies upon a system known as TrueTime to develop an agreed upon absolute truth which guides all transaction handling among the regional Cloud Spanner nodes. This system was essential when building an ACID-compliant and transactional system across a distributed architecture.
Planning for storage costs and performance
Cloud Storage is highly elastic and very cheap compared to on-prem data sources. This is achieved due to the incredible economies of scale afforded by the cloud. By utilizing best practices you can achieve an efficient cost optimization for storage data of any size in the cloud. As usual, there are trade-offs between cost and performance between different storage architectures.
Effective Use of Managed Services
Storage options in GCP are diverse and nuanced and require a thorough understanding of the various technologies as well as their most effective use cases. The proper choice for storage options can rely on a myriad of options depending upon how you want to process the data and which tools you need to use to accomplish your current task. As usual there are often trade-offs between the various choices offered including cost effectiveness, latency, interoperability with other processes, ease of ingestion and manipulation, and others.
Cloud Storage
Advantages and Tradeoffs
Cloud Storage is a go to storage option for basically any data. You can cheaply and efficiently store essentially any type of data with ease. The data in GCS can be used to feed a wide variety of different GCP services. By using the data as a BigQuery External Table you can use GCS as a data repository without having to go through additional data processing outside of BigQuery. GCS data is often used as a feeder for Dataproc as well and is an effective substitute for an HDFS file system.
GCS data has a robust API which can be used to trigger downstream events on certain actions performed on objects. For example, an application could deposit raw IOT sensor reading as a JSON file in a "quarantine" GCS bucket which would then trigger a Cloud Function. The function would read the data, validate the schema of the data or perform other data quality checks, check for PII using DLP, convert the file to Avro format and then deposit the data in a "clean bucket" which could then be read as an external table in BigQuery for analysis or be read using Dataproc to perform SparkML.
Cloud storage is not the quickest storage solution. For some situations requiring highly dynamic and low latency data access GCS it is not as ideal as other options. Additionally, the data isn't truly malleable, meaning you can't truly update an object in storage. When you perform an "update" on an object what is really happening is that a new object is uploaded and GCS changes the pointer of the object to reference the new version. This means that there is a slight delay (less than a second within a region) when perform CRUD operations on data in GCS. Creation of new objects can be read instantly, but updates to objects have a slight delay as GCS propagates the update to the various endpoints. This also means that it is possible to read old versions of the data, though unlikely.
GCS should not be used to house transaction data and is not an effective substitute for a RDBMS database. Although technology such as Spark or Snowflake can provide effective transaction management of the data in GCS this is more ideal for data processing, rather than low-latency transaction handling, which is better served by an RDBMS such as Cloud SQL or Cloud Spanner.
GCS is a great solution for hosting batch data which doesn't require highly dynamic operations and, when lifecycle options are properly configured, can make processing large amounts of data in GCP very cheap and easy. GCS can also be used to house static assets for websites and can also host static websites with very little work required from developers. GCS is not the proper choice if you are working with highly dynamic data requiring low latency operations, such as working with data on a website at the edge or when performing online ML predictions.
Cloud Storage supports compression, including BZIP2, DEFLATE, and GZIP. Compressing your files will help you save money on storage costs
BigTable
Advantages and Tradeoffs
Bigtable is a great solution for state management in web applications. It also can be used to track time-series data or financial transactions including stock price movements. It is also good for tracking IOT events and performing simple time series analyses on the events for anomaly detection or sliding window analytics. It is an effective state management tool, so it is often used in gaming to manage user state data such as character inventory or leaderboard statistics.
Similarly to GCS, Bigtable is not ACID compliant. Additionally, it is eventually consistent across clusters, so dirty reads are also possible between clusters and across regions. Cloud Spanner is built on top of Bigtable, but it is purpose built to process ACID transactions and uses highly specialized and complex processing techniques to achieve this and it would be almost impossible to replicate the logic outside of Google.
Use Bigtable to process low-latency time-series analyses. Bigtable can stream event data to dataflow which can then perform stream analytics or push the data into BigQuery for processing. Additionally, Bigtable data can be read directly from BigQuery when added as an external table. Just remember that Bigtable tables can have potentially thousands of columns and millions or even billions of rows of data to query.
Cloud Firestore
Advantages and Tradeoffs
Firestore provides SQL-like queries where you can query documents against specified elements in the document. This allows websites to pull only needed documents from Firestore as needed. Firestore offers listeners on the database which will monitor the database for CRUD operations on documents. These changes are captured and then streamed to any device which has a listener subscription. This can also be used to stream changes to documents directly to cloud functions where they can then be streamed into BigQuery, Pub/Sub or into GCS, which allows for event driven processing and stream analytics.
Firestore is a great choice for housing and maintaining low-latency website data and managing state. It provides strongly consistent, ACID transactions to manage web app data. For most sites which perform up to 500 operations per second against a given document, it is sufficient, but for websites or operations which require extremely fast and numerous transactions per second or requires effective state management at the edge, such as with some games or financial trading applications, consider using Memorystore at the edge as a buffer before writing to Firestore to permanently store data.
Firestore is not an analytical database. It is possible to run some basic SQL-like queries, but in practice these are mostly used to determine which documents to pull which are then passed onto another processor for aggregation, often this is a web server or edge device, such as a mobile phone. This is highly limited in expressibility and can't perform the highly complex queries possible in an RDBMS or analytical database.
Cloud Memorystore
Advantages and Tradeoffs
Memorystore is blazingly fast. It is capable of sub-millisecond response times of CRUD operations against objects in the database which is perfect for web applications. As a key-value store it is purpose built for caching commonly accessed data quickly and efficiently. However, Memorystore is not built for analytics and is not capable of complex analytical queries.
Memorystore is not ACID compliant and is not capable of relational database transactions and is not appropriate for handling highly sensitive operations, such as financial transactions. Memory store is ephemeral data and only lasts as long as the data exists in memory, therefore it is not useful as a long term storage layer or to house more than 300 GBs of data.
Cloud Spanner
Advantages and Tradeoffs
Cloud Spanner is often used by customers when they reach the hard limit of 25TB for Cloud SQL storage or if latency issues across regions becomes too great to use Cloud SQL alone. Since Spanner is an RDBMS it is logically possible to migrate from Cloud SQL to Spanner relatively easily, especially for PostGRES databases, which is what Spanner's interface and query language is designed to mimic.
Since Spanner is built on top of Bigtable it is subject to the same risks as Bigtable, such as hot-spotting. When migrating from Cloud SQL it may become necessary to rebuild certain schemas and relationships in order to maximize performance of Spanner.
Spanner is an effective tool and is great at what it does, however it is much more expensive byte per byte than Cloud SQL and this becomes prohibitive for most customers. If the data size and latency requirements fall within CloudSQL's limits then use CloudSQL.
Cloud SQL
Advantages and Tradeoffs
Cloud SQL is a classic RDBMS and is still appropriate for a wide variety of use cases. As a strongly consistent system Cloud SQL is well suited for ACID guaranteed transactions, such as financial transactions. It can also be used to host smaller data warehouses, though BigQuery is a better choice.
Cloud SQL instances can be configured to use Private IP addresses in support of Private Services Access. This is good if you need to shield the database from public access.
Cloud SQL will not be as quick at retrieving data as a distributed storage key value system such as Bigtable, Memorystore, or Cloud Spanner. Even with read replicas it simply can't match that level of performance. In order to help alleviate this for high demand workloads you can use Memorystore to cache common queries at the edge and provide a higher degree of dynamic application transactions.
Cloud SQL has a hard storage limit of 25TB.
BigQuery
Advantages and Tradeoffs
BigQuery can easily query massive amounts of data very quickly. When partitioned and clustered correctly BigQuery is also relatively cheap. As a serverless solution BigQuery doesn't require any server set up or configuration from users.
BigQuery has a built in ML solution, BQML, which allows users to run certain ML operations without ever having to leave the SQL environment.
BigQuery is not a transaction database and should not be used as one. It is not ideal for high frequency and dynamic queries at the edge. You can use Memorystore to cache common queries at the edge.
Lifecycle management of data
Data operates in cycles. Data is most useful when it is fresh and immediately available. This is also when it is accessed most frequently by users and stakeholders. As data ages, however, it becomes increasingly cost ineffective to have data in a high-performance state. Use effective lifecycle management techniques to mange your storage costs for infrequently accessed or archived data.
GCP has recently introduced an "auto-classification" system for GCS which will automatically reclassify objects on the fly depending upon user access patterns. This helps make storage utilization and costs more efficient and manageable. For the purposes of the exam you shouldn't worry about exact price points as these are subject to change. Instead focus more upon the factors that influence the price levels and how to architect your solution to best optimize your storage costs.
GCS prices are a product of three components:
- Storage - Amount and class
- Processing - Any processing performed by GCP, such as data access, replication, or retrieval
- Network Usage - the amount of data read from or moved between your buckets.
Generally speaking, the more data you store, the more you access it, and the quicker you need it, the more expensive it is. You can face fees if you attempt to access, alter, or delete data in certain classes without meeting quotas for that class. Auto-classification is great because it will automatically adapt to you particular data access patterns and ultimately save you money over the long term.
GCS Reference Table
| Storage Class | Minimum Storage Duration |
Retrieval Fees | Typical Availability |
|---|---|---|---|
| Standard | None | None | 99.99% |
| Nearline | 30 Days | Yes | 99.95% |
| Coldline | 90 Days | Yes | 99.95% |
| Archive | 365 Days | Yes | 99.95% |
Lifecycle Operations
A common practice is to set up lifecycle policies on your data in order to properly manage the storage classification of your data. You can set up rules to automatically move or delete data based on certain criteria, such as data not having been accessed or modified over a given timeline. A newer feature is to use Autoclass which will perform this action for you automatically, for a small fee per each thousand objects contained within. This is a great way to help cut down on storage costs and the operational overhead of user management.
In addition to storage classification management there are other valuable operations you should be aware of:
- Bucket Lock - A retention policy that says that an object must reach a certain age before being replaced or deleted (this includes updating the object!). This is useful for preventing accidental deletes and for controlling early delete fees.
- Object Retention Lock - Similar to the bucket lock, but applies to individual objects.
- Object Hold - an indefinite hold (lock) on an object until released.
- Object Versioning - This will retain previous instances of the object. In case the object is accidentally overwritten or destroyed it is possible to revert back to a previous version of the object. This actually negates the early delete charges for storage because the object is not actually deleted, it is made non-current. Object versioning cannot be enabled on a bucket that currently has a retention policy.
- Object Lifecycle Management - Sets rules governing object operations with a lifecycle configuration policy. You can use this to determine when an object is deleted, when it changes class, object locks, retention periods, or how many versions of an object you can keep. In order to apply an object must meet all conditions on the policy;.