Maintaining awareness of failures and mitigating impact
Leverage GCP's native stack to ensure high availability and distributed architecture. Use all the tools needed to manage risk according to the business requirements.
Topics Include:- Designing system for fault tolerance and managing restarts
- Running jobs in multiple regions or zones
- Preparing for data corruption and missing data
- Data replication and failover (e.g., Cloud SQL, Redis clusters)
GCP Professional Data Engineer Certification Preparation Guide (Nov 2023)
→ Maintaining and automating data workloads
→ Maintaining awareness of failures and mitigating impact
Topic Contents
Designing system for fault tolerance and managing restartsRunning jobs in multiple regions or zones
Preparing for data corruption and missing data
Data replication and failover (e.g., Cloud SQL, Redis clusters)
Designing system for fault tolerance and managing restarts
Errors and faults are inevitable when operating within the cloud. GCP offers a range of tools and best practices to quickly recover from failures in processing systems and ensure high availability and durability.
Designing System For Fault Tolerance And Managing Restarts
GCP, and cloud services in general, are highly resilient by design and are architected to provide high durability and availability. Depending upon the nature of your workloads you will either need greater support for failures and faults or less, and GCP provides the tools to facilitate any possible support requirements. In general, fault tolerance measures the ability for systems to recover from failure in a timely and persistent manner with zero or near-zero data loss.
Google builds and operates its own networking hardware and infrastructure. This allows for global replication and fault-tolerance for nearly every service. Multi-region architectures are mathematically guaranteed to be durable and available.
Cloud Storage
Cloud Storage is extremely durable regional object storage. Cloud Storage is designed for 99.999999999% (11 9's) annual durability. This is achieved with automatic zonal replication and only catastrophic physical destruction of an entire region would destroy your data. Additionally, Cloud Storage is also highly available when reading objects. In case of a zonal failure Cloud Storage will automatically route requests to another zone, ensuring a seamless experience for users.
BigQuery
BigQuery is a serverless service and was architected from the beginning to be highly available and fault tolerant. In the back end architecture your data is replicated dozens of times across zones, racks, and nodes within regions. 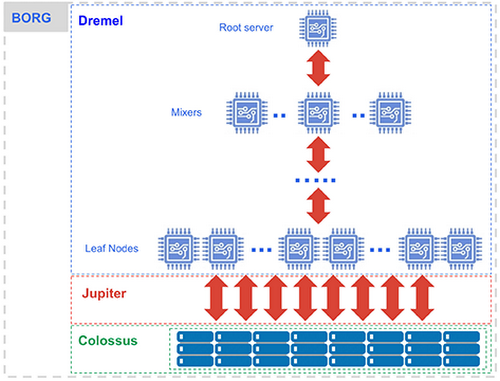 When queried, BigQuery spins up thousands of microcomputers to query your data. If one of these machines fails another is seamlessly picked up by Dremel (The Query Engine) and the query continues. In practice it is almost impossible for a query to fail due to a mechanical failure on behalf of Dremel. Dremel is optimized for large scale queries across dozens of nodes, racks, and servers. This highly scalable and fully serverless architecture gives BigQuery a distinct advantage as a cloud data warehouse, enabling seamless integration with other GCP services and essentially zero maintenance or management on behalf on the user.
When queried, BigQuery spins up thousands of microcomputers to query your data. If one of these machines fails another is seamlessly picked up by Dremel (The Query Engine) and the query continues. In practice it is almost impossible for a query to fail due to a mechanical failure on behalf of Dremel. Dremel is optimized for large scale queries across dozens of nodes, racks, and servers. This highly scalable and fully serverless architecture gives BigQuery a distinct advantage as a cloud data warehouse, enabling seamless integration with other GCP services and essentially zero maintenance or management on behalf on the user.
BigTable
Bigtable is robust and fault tolerant by default. Data are automatically replicated across multiple shards and in the case of a fault a new shard automatically activates to provide the service. Bigtable replicates data in multiple clusters across zones. The replication is eventually-consistent, however, and therefore is not ACID-compliant across zones. You can enable strong consistency at the cost of latency.
Dataflow
Dataflow, like BigQuery, is a serverless and fully managed service. It is fault tolerant by default and will automatically recover from failures without any user input. Dataflow does not store persistent data outside of what is required at process-time, so therefore durability of data is not a concern.
Cloud Spanner
Cloud Spanner is built on top of Bigtable, but is globally available, and ACID Compliant. As a serverless and managed service, Cloud Spanner is globally replicated and fault tolerant by default without any user input. Gmail is a Spanner application, for example.
Cloud SQL
Cloud SQL's durability and availability are largely dependent upon the database software you are hosting, but GCP's Compute Engine can be measured. Operating a single node architecture is not a guaranteed solution, but a persistent disk can ensure no data loss in the event of failure. It is also wise to take periodic snapshots of the disk as a backup.
Running jobs in multiple regions or zones
GCP gives you the tools to run tasks across geographical boundaries to take advantage of high availability and durable architectures.
Running jobs in multiple regions or zones
If your organization is operating in multiple geographic locations it can be a good ideal to replicate your services across regions to better serve your customers, provide a better service with lower latency, and achieve high-availability and durability. Most managed services in GCP operate this way by default.
BigQuery
BigQuery is multi-zonal by default, and datasets are tied to a specific region. When querying BigQuery the service automatically chooses the most performant endpoint per request. When performing data replication across regions you can program your Cloud Load Balancer to redirect queries to a closer endpoint to the request which can reduce latency and load on resources.
It should be noted that there is a so called "multi-region" datasets usable by BigQuery, but, in reality, this simply allocates more slots to be used across the regions. The actual data is still only stored in one region unless you replicate it to another region.
Bigtable
Bigtable has easy built-in configurations for setting up multi-cluster routing which will replicate your cluster to two zones in a region. If you want to serve data in multiple regions Bigtable allows easy multi-region and multi-cluster deployments and BigTable will automatically point requests to the closest endpoint. Just be aware that Bigtable is eventually consistent and follows a "last write wins" implementation of data, which means that if there are two writes to the same dataset Bigtable will commit the last write event as the consistent state.
Cloud Spanner
Cloud Spanner is a global service by default and is automatically replicated to achieve high-availability and high-durability. Spanner automatically routes requests to the closest endpoint geographically. This allows a very high level of database performance while still achieving ACID-compliance.
Preparing for data corruption and missing data
Like faults and errors, data corruption is inevitable. Prepare for data failures and corruption by identifying, isolating and quarantining corrupt or missing data.
Preparing for data corruption and missing data
Data corruption is an inevitability for any cloud computing environment and deployment. By taking proactive steps to isolate and recover from data corruption you can ensure a high-performing and high-quality data engineering solution.
Pub/Sub Schemas For Streaming Data
A great way to ensure a high quality data product is to ensure that bad data doesn't make it into your system in the first place. Use Pub/Sub Schemas to create a data contract between source and destination. This contract will enforce data quality standards at the ingestion layer and any message that fails the schema check will be relayed to a dead-letter queue where the message can be examined and debugged.
Be prepared for duplicated when using Pub/Sub as Pub/Sub offers only a guaranteed at-least-once delivery with the possibility of duplicates. If you start to see a large number of duplicates occurring in your system then it is possible that you are not properly acknowledging the messages.
Batch Data
Batch data loads usually flow into Cloud Storage for processing. In this case, it can be difficult to diagnose data quality issues immediately. One option is to flow the batch data into a quarantine area first. Then you can use python, Dataprep, Dataflow, or an external stage in BigQuery to examine the data for quality issues before loading into a clean bucket for further processing. This is also useful if you have incoming data from sensitive sources. You could put the data in the quarantine bucket and examine it with Cloud DLP before further processing.
Missing Data
Missing Data can be identified with Cloud Dataprep's data profiling tool, Data flow aggregation, or BigQuery profiling query. It is always a good idea to check against the source to ensure that you have all the rows you should.
Cloud Dataplex
Cloud Dataplex has built in tools to perform data quality tasks. Use these tasks to automatically run data quality checks against data in Cloud Storage and BigQuery. There are a large number of possible data quality checks you can perform. You don't need to memorize them all, but know that this is the future that GCP is striving towards.
Data replication and failover (e.g., Cloud SQL, Redis clusters)
GCP's managed services can be made highly available by default to ensure successful and high-performance operations in the event of failures.
Data replication and failover (e.g., Cloud SQL, Redis clusters)
BigQuery
BigQuery is a regional service which high availability between two zones by default. In the event of a soft failure, such as a large power outage effecting regional network access, you will temporarily be unable to use BigQuery, but your data will not be lost. In the event of an extremely unlikely cataclysmic physical regional destructive event your data will be lost. To prevent this you can copy dataset data from one region to another via the BigQuery transfer service. You can also use Cloud Composer to copy the datasets or export the data to GCS as a backup. The most likely use case for this is to guard against a regional outage via hot-hot availability so that your processes can fail over to a secondary replicated region.
BigTable
BigTable can be configured for automatic or manual failovers in the case of a cluster outage. Data can be replicated across regions and zones. With multi-cluster replication, automatic failovers, and nearest cluster routing enabled you are well protected in the case of a cluster failure.
If you are using single-cluster routing then you would have to point the requests to the secondary cluster manually.
Cloud Storage
Cloud Storage is highly durable by default across zones. If you want to go even further you can use dual-region or multi-region bucketing. This ensures durability and eventual consistency via asynchronous requests. To take the next step to ensure a true high-availability set up, you can use GCS Turbo-Replication to replicate data with dual-region set ups instantly and synchronously to ensure strong consistency among Cloud Storage objects.
Cloud load balancer will automatically reroute requests to a secondary bucket if the first region fails.
Cloud Composer
Highly resilient Cloud Composer environments are Cloud Composer 2 environments that use built-in redundancy and failover mechanisms that reduce the environment's susceptibility to zonal failures and single point of failure outages. This enables high-availability for Cloud SQL powering Cloud Composer. This is only available with a private IP.
Cloud SQL
Cloud SQL high-availability set ups are designed to protect against zonal failures within a single region. HA Configuration provides data redundancy by creating read replicas in multiple zones. In the event of a zonal failure containing a primary instance Cloud SQL will fail over to the read replica and promote it as the primary instance. Once the other zone is back up Cloud SQL will maintain the new primary instance and rebuild the read replica automatically.
In the case that multi-zonal replication is insufficient, you can enable cross-region read replication. This has a few benefits such as giving requests access to close read instances and ensuring high-availability across regions. In the event of a regional outage Cloud SQL will automatically promote the instance in the other region. An absolute bullet-proof set up would be a 3 Zone HA replication within 3 different Regions.
Memorystore for Redis
Memorystore for Redis offers high-availability architectures. Redis HA is regional only and zonally partitioned. Each zone contains a primary node which can be replicated to one or two alternative zones. In case of a failure requests are rerouted to the secondary replica, client connections will be reset. It will take less than a minute to switch to the new replica and few minutes to rebuild the failed node.