Exploring and analyzing data
Exploring and analyzing data is useful precursory step when performing feature engineering in preparation for machine learning development. Learn some techniques for data discovery and feature engineering in GCP's common data stack.
GCP Professional Data Engineer Certification Preparation Guide (Nov 2023)
→ Preparing and using data for analysis
→ Exploring and analyzing data
Topic Contents
Preparing data for feature engineering (training and serving machine learning models)Conducting data discovery
Preparing data for feature engineering (training and serving machine learning models)
GCP is capable of high performance data analytics and machine learning. As a Data Engineer, you could be tasked to help data science teams in machine learning projects. This includes developing datasets for further exploitation by feature engineering.
Preparing data for feature engineering (training and serving machine learning models)
In addition to GCP's robust and high-performing data analytics platform GCP also offers a powerful machine learning ecosystem. Google Cloud has a number of machine learning and data science tools which can drive deep insights and analysis. Before any machine learning begins, however, you must perform feature engineering.
Feature Engineering, feature extraction, or feature discovery is the process of extracting features from raw data. Data scientists and machine learning engineering are the ones usually tasked with performing feature engineering, but as a Data Engineer, you could be tasked with developing the datasets which are used for data exploration and feature engineering.
Data engineers use many of the same tools as used in other GCP data engineering tasks, such as reporting, curating and cataloguing data, but the tools would be used in different ways. For example, financial reports are usually very strict in regulation and requires extreme scrutiny when developing and publishing. All data points must be guaranteed to be accurate and complete. However, an analytical engine using machine learning might only be working with sample data and would instead rely upon statistical methods to extrapolate likely values from measured inputs. This precludes the need for perfect and complete data, and instead is almost fully based on statistical reasoning.
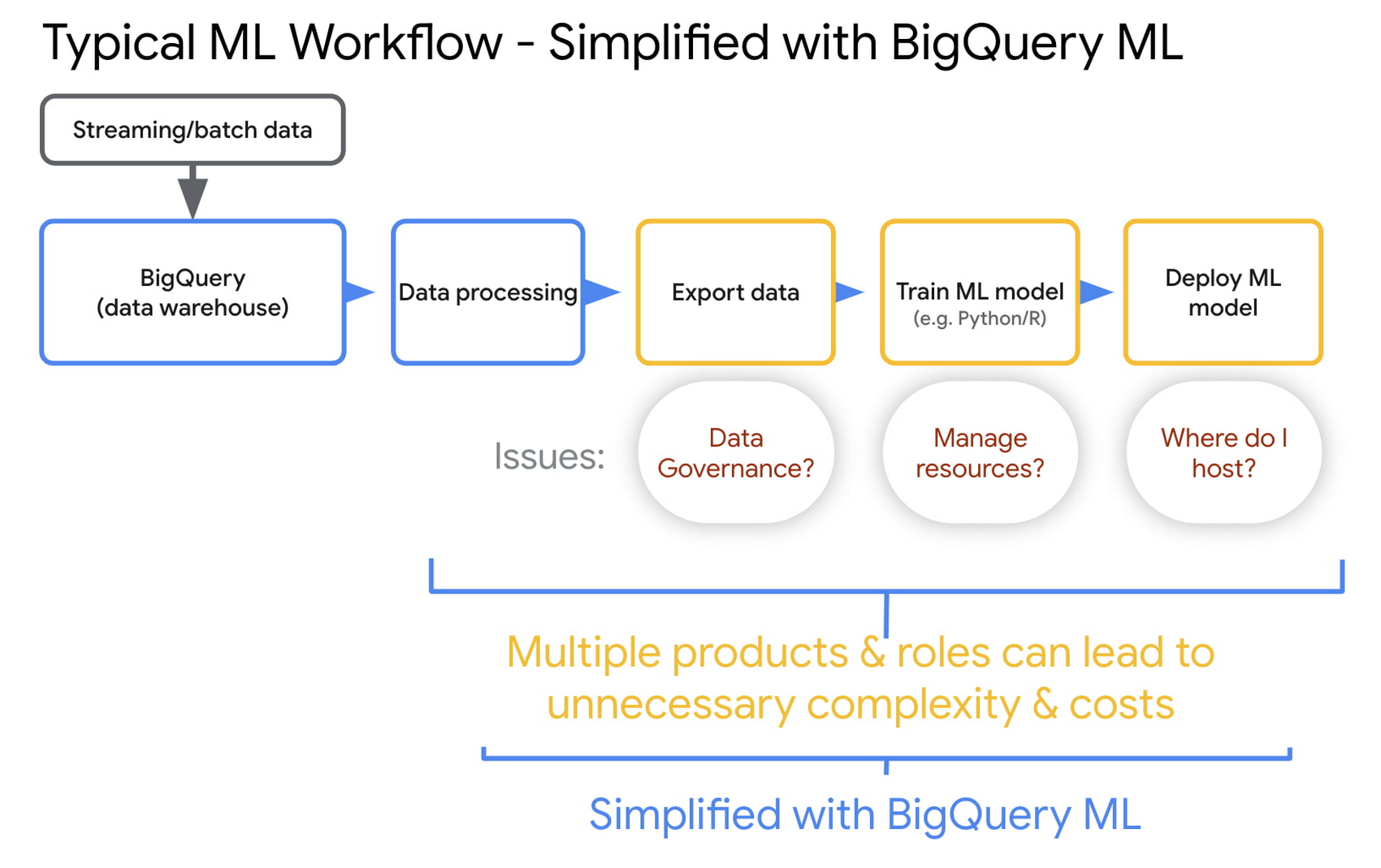
BigQuery ML
BigQuery ML is a highly capable and SQL Native ML solution hosted solely in the BigQuery infrastructure. This has a few key advantages over other solutions. As a SQL-Native solution you don't have to program complex and expensive python or Java models and infrastructure from scratch, instead you can use SQL to do everything. Additionally, since BigQuery ML is BigQuery native the data do not have to change environments to be operated on which greatly speeds up the execution flow of the data.
BigQuery ML is a great solution if your ML solution doesn't require highly complex custom training. You could build an entire MLOps workflow in BigQuery without ever having to leave the SQL environment. A BigQuery ML solution can use SQL to perform data ingestion, pre-processing, feature engineering, training, testing, evaluation, hyperparameter tuning, deployment, and predictions.
Supported Models
BigQuery is highly capable, but it can only support models which can be distributed over a warehouse table, basically this means numbers and text analysis only. BigQuery cannot be used for object detection, image recognition, chatbots, etc. And, of course, any ML solution is only as good as the data which is used to train it and predict with it. So it is important to get the data preprocessing and feature engineering correct before even attempting to build the ML model.
Different models are good for certain objectives. Reference the BigQuery ML Model Selection Guide for a good outline of which models to choose for a given use case. The exam expects you to know which models BigQuery ML supports and their proper use cases, but you don't have to know the complex mathematics behind the algorithms.
| Supported Model | Supported Objectives |
|---|---|
| Linear Regression | Linear Regression is for forecasting. For example, this model forecasts the sales of an item on a given day. Labels are real-valued, meaning they cannot be positive infinity or negative infinity or a NaN (Not a Number). |
| Logistic Regression | Logistic Regression is for the classification of two or more possible values such as whether an input is low-value, medium-value, or high-value. Labels can have up to 50 unique values. |
| K-means clustering | K-Means Clustering is for data segmentation. For example, this model identifies customer segments. K-means is an unsupervised learning technique, so model training doesn't require labels or split data for training or evaluation. |
| Matrix Factorization | Matrix Factorization is for creating product recommendation systems. You can create product recommendations using historical customer behavior, transactions, and product ratings, and then use those recommendations for personalized customer experiences. |
| Principal Component Analysis (PCA) | Principal Component Analysis (PCA) is the process of computing the principal components and using them to perform a change of basis on the data. It's commonly used for dimensionality reduction by projecting each data point onto only the first few principal components to obtain lower-dimensional data while preserving as much of the data's variation as possible. |
| Time Series | Time Series is for performing time series forecasts. You can use this feature to create time series models and use them for forecasting. The model automatically handles anomalies, seasonality, and holidays. |
Remote, Imported, or Externally Derived Models
You can import remote models that are trained in external sources and make predictions on them in BigQuery. This is rare and it is more likely that you would see these models in a true Vertex AI workflow with BigQuery data hosted as a dataset.
Supported Models include:
- Open Neural Network Exchange (ONNX)
- TensorFlow
- TensorFlow Lite
- XGBoost
MLOps with BigQuery ML and Vertex AI
Ml Ops can be enabled for BigQuery ML solutions via Vertex AI Model Registry. Creating a true MLOps pipeline for BigQuery ML can ensure protections against common machine learning pitfalls (such as data drift or feature skew) as well as ensure an efficient and easily modifiable solution using a CI/CD pipeline.
Like many other Vertex AI solutions you can build the entire workflow using a Vertex AI Notebook.
Feature Engineering in BigQueryML
BigQueryML can perform advanced feature engineering either automatically or by using the Transform clause to perform manual preprocessing. Features created from here are then fed into Vertex AI feature store and can be operationalized and be used in ML models. The actual SQL Statements used to perform this modeling are beyond the scope of the test, but be aware of BigQuery ML's capabilities.
Deploying a BigQuery ML Solution
BigQuery ML Batch Predictions
BigQuery ML can serve batch predictions with a simple python program and a SQL query. Vertex AI can be used to query the BigQuery model and return results without requiring a true Vertex AI endpoint.
BigQuery ML Online Predictions
Vertex AI can make online real time prediction if you deploy BigQuery ML to a Vertex AI endpoint. For the purposes of the exam you only need to understand that Vertex AI enables online predictions with BigQuery ML.
Data Ingestion
BigQuery ML operational efficiency is highly dependent upon your BigQuery ingestion. All raw data should be ingested, processed, transformed, and modeled in BigQuery. Combine this with Dataplex or Analytics Hub to quickly find and leverage pre-built models and features.
Conducting data discovery
Data discovery is the art of finding and analyzing datasets within GCP. Use tools such as Data Catalogue and Analytics Hub to discover data relevant to your solution or use case.
Conducting data discovery
Dataplex, Data Catalog, and Analytics Hub are ideal for discovering and leveraging data to use in your machine learning models. Dataplex can use federated governance to ensure that only high-quality and production ready data are used for your models. Analytics Hub can be used to connect you with data from outside your organization and greatly enrich the features your model can consider.
Dataplex Discovery will automatically scan for and detect new data or objects which enter proscribed sources, such as Cloud Storage Buckets or BigQuery Datasets. If Dataplex detects blob files, such as images, it will surface these as "filesets". If Dataplex discovers proper files in GCS, such as a collection of CSV's, JSON data, etc. it will create BigQuery External Tables automatically for these datasets and make them available for querying.
Dataplex can be used to integrate BigQuery data profiling with Data Catalog to automatically map and make available detailed data profiles for any BigQuery table. If you have built a data mesh with dataplex you can use integrated dataplex monitoring with automatically captured metadata which can report on data quality data points such as data freshness and availability. If you notice that data freshness is lagging this could be a sign of some material change in your queries which are resulting in a delayed result set. Used in combination, data profiling and data quality checks provide a robust and powerful suite of capabilities for your users.